35 Discuss the rationales behind network optimization.
The most important aspect of the network administrator's job is to ensure availability of data as without the same organizations cannot function. To achieve the same, the policy adopted by administrator follows revolves around:
- Fault Tolerance and
- Disaster Recovery.
The reason for the same is Uptime. One of the basic requirements that are expected of routers, cables and servers is availability. The complete performance of the network depends on the availability of the various devices. Failure of even a single device means productivity of the organization is affected. The loss that an organization has to suffer would depend on the amount of dependence the organization has on the network. The network may be claimed as 100 per cent available, but this statement cannot be said to remain true in all circumstances. At some or the other stage of the life of a network it fails, resulting in a loss.
The important question that has to be determined is what is a realistic aim for a network administrator to achieve? The table given below illustrates the loss in number of hours depending on the availability.
|
Level of Availability |
Availability % |
Downtime per Year |
|---|---|---|
|
Commercial Availability |
99.5% |
43.8 hrs. |
|
High Availability |
99.9% |
8.8 hrs. |
|
Fault Resilient |
99.99% |
53 mins. |
|
Clusters | ||
|
Fault Tolerance |
99.999% |
5 mins. |
|
Continuity |
100% |
0 |
Table 9: Levels of Availability and Downtime
The figures mentioned in the column heading downtime are the impetus behind spending money on bringing in fault tolerance measures in the system. To achieve commercial availability a number of measures have to be incorporated cumulatively and with every level the expenses involved may also increase. As the administrator works for a fault resilient system the expenses grow and the returns diminish. The network administrator performs a critical role at this stage. He has to make the management agree to the expenses to be incurred. The management has to be made aware of the potential risks and the ensuing effects of each failure. The network administrator has to inform the management that a working network is different from an efficient network.
Fault Tolerance: Fault Tolerance is the term used to describe the ability of a device to keep functioning even when there is a failure. Fault Tolerance measures increase the uptime of a device. The failure could be of the hardware or the software.
Fault Tolerance is different from disaster recovery. Disaster Recovery is the ability of the system to recover in case of a disaster. Loss of data and availability means loss of money. The ability to recover refers to no loss of data and no loss of availability. Fault tolerance measures would also not come free. It is all about measuring, balancing the pros and the cons. Loss Designing, or working for such a system is not easy, and many factors need to be taken care of.
The Risks Involved: Having a conducive system against equipment failure is an absolute essential. There is some equipment that is more likely to face a failure than others are. The approximate figures of failure of hardware components are illustrated in the pie chart given below.
Controller Motherboard
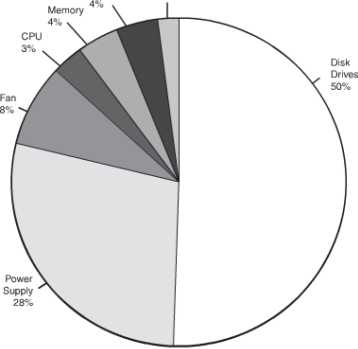
Figure 58: Server Component Failure Percentage
As it is clear from the graph given above that a hard disk is one of the major reasons for downtime. A fault tolerant solution can be a specialized solution or a simple act of maintaining a duplicate network card. Some of the fault tolerance measures that can be incorporated are:
- RAID: For every component prone to failure, measures have been designed to cope up with the same. Redundant array of inexpensive disks (RAID) is a set of standards that has been developed to deal with failures of the hard disk. It uses a combination of multiple hard disks in a manner that ensures that more than one disk stores the data at a given point of time. The advantage is that the availability of data is not compromised in case of a failure and it works faster than using a single disk. It enhances performance of the hard disk.
- Link Redundancy: A fault in a NIC has the potential of disabling access to the data. Various strategies can be adopted to deal with this. Some of the systems may use a hot spare in the system that can be used the moment a failure comes across. Even though the probability of a failed network card is low, still a strategy to reduce the same even further has been designed. The process is known as adapter teaming. In this configuring of a group of network cards is done in a manner allowing them to act as a single unit. Teaming is done using software and the results are received in the form of fault tolerance accompanied with increased bandwidth and better traffic management. The features can be categorized in three sections:
- Adapter Fault Tolerance: With the help of basic configuration, it is possible that a network card be configured as a primary device and others as a secondary device. In case of failure of a primary adapter, the secondary adapter can step in.
- Adapter Load Balancing: Software controls enable that the workload be distributed in a manner that ensures that each link has been used to a similar extent. This ensures that no single card is over burdened.
- Link Aggregation: This works by combining the transfer rates of more than one network card.
- Using uninterruptible power supplies (UPSs): Power issues can never be ignored while discussing fault tolerance measures. Uninterrupted power supply (UPS) is the device that takes care of a regular power supply. It is a battery capable of built in charging and performs many functions when it comes to server implementations. In times of good power, the same gets charged and the battery is used in case of power failures. The objective is to ensure a safe shutdown of the server. The reasons that make a UPS necessary are:
- Availability of Data: Access to the server is assured as long as the data is being saved by the UPS even in case of power failure.
- Loss of Data due to Power Fluctuations: Power fluctuations do not work well with data on the server system. The data lying in cache could be lost in case of voltage fluctuations.
- Damage to the Hardware: Power fluctuations are not good for the hardware components within a computer.
- Using redundant power supplies: Failure of power supplies is a common issue, but a critical one on servers. Powering down in order to replace a faulty supply is not easy in the case of servers. The server can be prepared for a fault power supply by redundant, hot-swappable power supplies. No doubt there are heavy costs involved but the same have to be measured against advantages of continued power supply.
- Setting up standby servers and server clusters: There are organizations that incorporate complete servers in a fault tolerant design. This ensures that the entire system is up and working. For doing these two strategies can be adopted:
- Standby Servers: In this a completely configured server is available as a standby. This becomes available in a short span of time. The second servers are made available at alternative locations. Another variation of this strategy is the option of server failover. In a server failover, two servers are wired together and one acts as a primary server whereas the second one is a secondary server. The moment the secondary server realizes that the primary on is offline, it takes over. Both the versions are not cost friendly.
- Servers Clustering: This strategy is adopted by organizations for which even a few seconds of downtime could prove crucial. In this several computers are grouped together in a single logical unit. This provides for fault tolerance as well as load balancing. A server cluster takes over in a failure without any downtime as the clusters are always communicating and compensate for each other. It works on the five nine principle that is 99.999% uptime. The only disadvantage with this system is the cost factor with many advantages. The advantages are:
- Increased Performance;
- Load Balancing;
- Failover and
- Scalability
- Preparing for Memory Failures: Memory once installed generally works in an error free mode. But memory can be the root cause of many problems. Hot swapping is not a possibility to work with in the case of problems with memory. The server has to be powered down in case memory has to be replaced. There are environments which support memory replacement. This cannot be done without putting in due considerations.
- Managing Processor Failures: Processors as a part of the system are designed in a manner that is fault tolerant largely. There are environments that can have standby servers ready.
Disaster Recovery: Disaster Recovery is undertaken when the fault tolerance measures fail. Backups and Backup strategies form the essentials parts of disaster recovery.
Backup Methods: There are several backup methods that can be chosen from. The choice of the method that is used for backup is controlled by the needs of the organization and the time that is available in which the backup must be taken. Backup is undertaken through a window and conducting the same outside the window tends to slow down the server. The different backup methods that are available are:
- Full Backups: Also known as a normal backup it is the best type of backup that can be opted for. All the files are copied on the hard disk in this backup and the system can be restored with the help of a single set of files. This is not always seen as the best option as the quantum of data could be enormous and the same could take a long time. Administrators try to take full back ups during the off hours or do it at a time when the load on the servers is the least. These serve well in smaller setups with a limited amount of data. The determination of files that have been altered since the last time is done by a software with the help of a setting known as the archive bit.
- Incremental Backups: This is a much faster backup than full backup. In incremental backup, only the files that have experienced a change since the last incremental backup are included. It has to copy comparatively less amount of data than the full backup. The limitation is that the restoration of the files is done at a much slower rate. It requires that the full backup tape and the incremental backup tapes taken since the time the data has to be restored to be taken along. It is also necessary to store the incremental tapes in a chronological order
- Differential Backups: In the case of differential backups, the files that have been changed or created since the last full backup are recorded. The advantage of this type over incremental is that it requires only two tapes to be considered; the full backup tape and the latest differential tape. These fall in the middle of full and incremental backups.
Backup Rotation Schedules: The backup methods are used along with backup rotation schedules. The most common and popular rotation schedule is the GFS rotation that is the Grand Father Son Rotation. Following this method separate tapes are recorded on daily, weekly and monthly basis. It uses twelve tapes in total, four tapes for daily backup -Monday to Thursday and called the son tapes; five tapes for the weekly backup every Friday known as the Father tapes and three tapes for the monthly backup which are known as the grandfather tapes. This rotation method allows recovery of lost data from the previous day, previous week, and previous month. As more number of tapes are added, the complexity of the rotation increases.
Storage of Backup: It is tempting to the store the backups on the site itself, but this should be discouraged, keeping in view that the site may become inaccessible for some reasons and as a result, access to the backup may not be feasible.
When working on the backup strategy, the points that need to taken care of are:
- Conduct efficacy tests on the backup once it is complete;
- Update and check the backup logs for errors;
- Do not forget to label the back up tapes;
- Encourage offsite storage of the backups;
- Periodically change the tapes on which backup is stored as they are prone to wear and tear;
- Do not forget to protect your backup with passwords.